
What are the differences between threads in Python and threads in other programming languages? What is the GIL? Is it always more efficient to use multithreading and multiprocessing over single-threading and single-processing? In this article, I will discuss the limitations of threads in Python and provide recommendations on when to use multithreading, multiprocessing, or stick with single threading. I have applied knowledge at zen8labs every day with Django application.
Properties of Thread and Process in Python
Thread
- Cannot run multiple threads at the same time
- When forking a new thread, the code segment and global data segment are shared between threads → no time is wasted like forking a new process
Process
- When fork a new process, the entire data and code segment are copied to the new process → time-consuming
Benchmark
There are 2 types of tasks in Python:
- Interactivity with IO such as calling HTTP API, reading files…, – IO bounded
- Complex computation, using multiple CPUs – CPU bounded
There are 2 parallel processing methods in Python:
- Multithreading
- Multiprocessing
We use the following program to test the efficiency of multithreading/single-threading and multiprocessing/single-processing in the 2 types of tasks.
- measure: function is used to measure the execution time of a function.
- fib: function is the Fibonacci number calculation function, representing the task that uses multiple CPUs.
- get_user: function is the function that calls the API from Github, representing the IO-bound task.
import threading
import multiprocessing
import time
import requests
def measure(func):
def f(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
print(f"{func.__name__} takes {time.time()-start} seconds")
return ret
return f
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)
def get_user():
return requests.get("<https://api.github.com/users/magiskboy>")
@measure
def cpu_bounded_in_multiple_process():
p1 = multiprocessing.Process(target=fib, args=(40,), daemon=True)
p2 = multiprocessing.Process(target=fib, args=(40,), daemon=True)
p1.start()
p2.start()
p1.join()
p2.join()
@measure
def cpu_bounded_in_multiple_thread():
t1 = threading.Thread(target=fib, args=(40,), daemon=True)
t2 = threading.Thread(target=fib, args=(40,), daemon=True)
t1.start()
t2.start()
t1.join()
t2.join()
@measure
def cpu_bounded_in_single_thread():
fib(40)
fib(40)
@measure
def io_bounded_in_single_thread(n_iters=10):
for i in range(n_iters):
get_user()
@measure
def io_bounded_in_multiple_threads(n_iters=10):
ts = []
for i in range(n_iters):
t = threading.Thread(
target=get_user,
daemon=True,
)
t.start()
ts.append(t)
for t in ts:
t.join()
if __name__ == "__main__":
cpu_bounded_in_single_thread()
cpu_bounded_in_multiple_thread()
cpu_bounded_in_multiple_process()
io_bounded_in_single_thread()
io_bounded_in_multiple_threads()
Observations
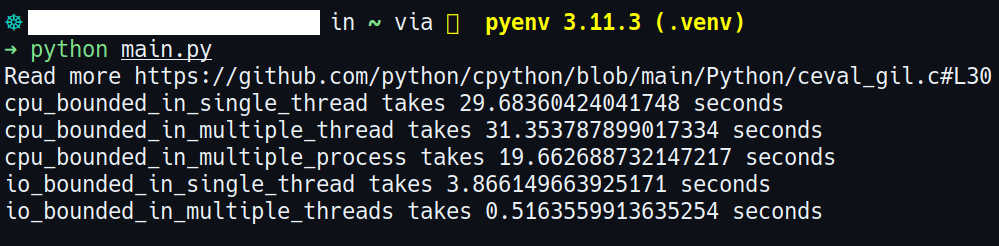
- For IO-bound tasks, multithreading is more efficient than single-threading.
- For CPU-bound tasks, multiprocessing is more efficient than multithreading.
- For CPU-bound tasks, single-threading is more efficient than multithreading.
The result of the benchmark program
Q&A
Q: Why is multithreading more efficient than single-threading for IO-bound tasks even though we cannot run multiple threads at the same time in Python?
A: In IO-bound tasks that do not use CPU, when a thread is locked, that thread is still considered running because the time locked overlaps with the time waiting for the IO result. Therefore, parallelism is partially guaranteed.
Q: Why is multiprocessing more efficient than multithreading for CPU-bound tasks?
A: In Python there is no multithreading because only 1 thread can run at a time. With multiprocessing, multiple processes can run at the same time.
Q: For tasks that use multiple CPUs, why is single-threading more efficient than multithreading?
A: In Python, only 1 thread can run at a time, so even if multiple threads are running, parallel processing does not occur. In fact, multithreading is less efficient in this case because of the context-switching overhead.
GIL – Global Interpreter Lock
GIL is a mutex lock used to ensure that only 1 thread is executed at a time.
Mutex lock will lock the entire data segment of the entire process for other threads and only the executing thread can access that data segment.
Only use 1 mutex lock for the entire data of the process has 2 reasons:
- Avoid deadlock
- Reduce the cost of updating the status of mutex locks, avoiding overhead
You can read more about GIL in here
Conclusion
For IO-intensive tasks, multithreading is beneficial as it allows the program to continue executing while waiting for IO operations to complete. However, for CPU-intensive tasks that require significant computation, multithreading is generally ineffective due to the Global Interpreter Lock (GIL) in Python, which limits execution to one thread at a time. Instead, optimizing the program for efficient single-threaded execution is recommended. If the computation is particularly demanding, multiprocessing can be used to leverage multiple CPU cores, enabling true parallel execution and improving performance.
If you want to learn more about a range of IT topics then read some of our zen8labs blogs, we cover all angles to give you the tools to create something awesome!
Thanh Khac Nguyen – Software Engineer


