One of the most effective strategies for improving performance is ensuring the right indexes are in place for your table columns. Indexes can significantly reduce query times by optimizing data access, helping retrieve results as quickly as possible.
PostgreSQL offers different ways to utilize indexes to produce the most efficient execution plan. In this blog, I’ll review the following three different PostgreSQL scan types, showing how they vary based on the table, the queries that are retrieving, and the applied filters:
- Bitmap index scan
- Index Scan
- Index only scan
Building the testing scenario
To help us understand the index scanning steps, we will create our testing scenario. Let’s use one table with a single index for the following exercises and examples and review how the scan strategy can change depending on the query conditions.
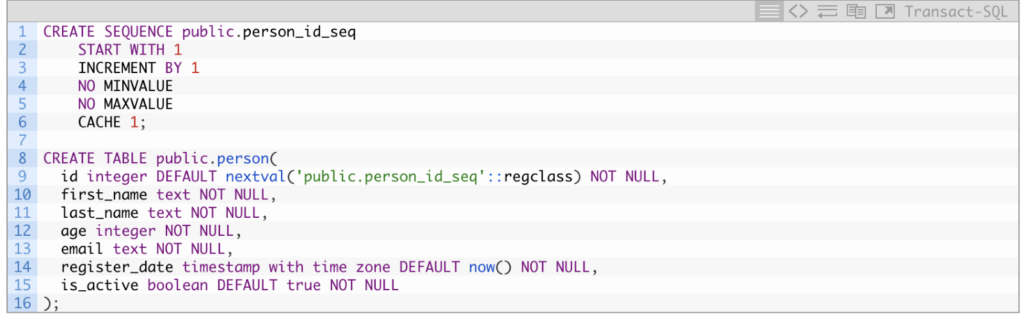
The next step is the table definition, where I have also included a sequence creation statement for the id column. This is because it is best practice to always have a primary key column, although for the specific examples we will explore, it won’t be strictly necessary.
Taking some inspirations from the How To Generate Test Data for Your Database With SQL Percona blog, we will use the following SQL statement to insert ten million rows to this table:

Now that we have our test table populated with some dummy data, we can begin practicing.
Indexing the data
As mentioned earlier, the best practice is to add a primary key for the table. However, for this example, we will skip this step and add only a composite index to help us review the different scan types.
We create this multicolumn index as follows:

In this example, we consider three columns with different cardinalities, meaning the proportion of distinct values are about the total number of rows. The following are the columns ordered from the higher to the lower cardinality:
- register_date. We loaded the 10M rows setting this column with the help of the random() function, so the number of distinct values is the largest of these three columns.
- age. When we loaded the data, we also used the random() function, but we “limited” the results with the floor() function, so all the different values are between 1 and 99.
- is_active. This column data type is boolean, meaning it only has two different values are possible, true and false.
It is essential to think about the data cardinality of a column when planning the indexes and, even before that, the filters we will execute against the data.
For example, in the above columns, having a single index over the is_active columns will not add any advantage because, from all the 10M rows, only two values are possible, so if we would want to filter all the is_active = true rows, the planner will use sequential scan with no doubt.
One way to verify a column’s number of distinct values is by querying the pg_stats view in our database. For this is important to ensure the statistics are fresh; in this case, we run the ANALYZE command:

For the previous columns, the following is the result of querying the pg_stats view:
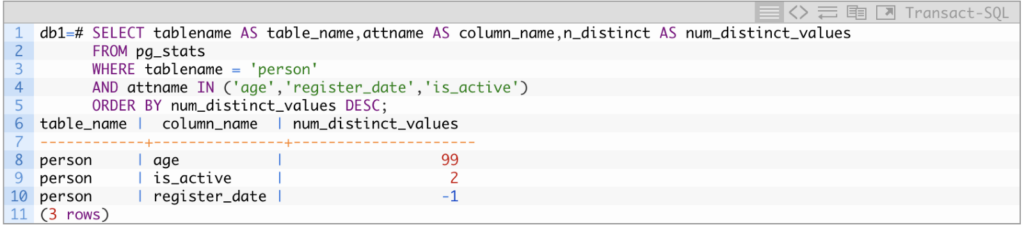
And we confirm that the age column has 99 distinct values whereas is_active only 2. The register_date column shows a negative value of -1 because, as described in the documentation, the ANALYZE believed the number of distinct values is likely the same as the total number of rows.
One index, different scan types
Now that we have the table data and the index in place, we can test different scan types. First, and to have a starting point, let’s verify how PostgreSQL resolves a query that retrieves all the table data with no filters:

As expected, to retrieve all the data from the table, the planner decided on a Sequential Scan, going for all the 10M rows. It makes sense since it is getting all the rows at once. The total time it took was over 1183ms (~1.1sec.).
Bitmap index scan
The planner chooses this index scan method when the query asks for a large enough amount of data that can leverage the benefits of the bulk read, like the sequential scan, but not that large that actually requires processing the WHOLE table. We can think of the Bitmap index scan as something between the Sequential and Index scan.
The Bitmap index scan always works in pair with a Bitmap heap scan; the first, scans the index to find all the suitable row locations and builds a bitmap, then the second use that bitmap to scan the heap pages one by one and gather the rows.
The following is an example of a Bitmap index scan using the table and the index we built before:
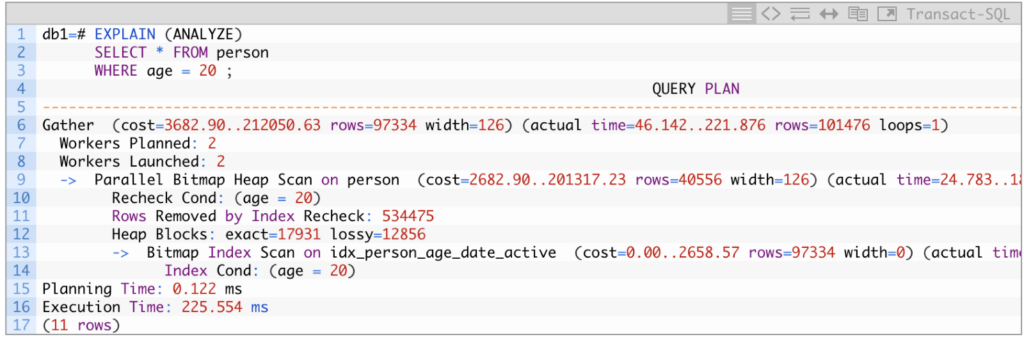
In the inner node (which executes first) is a Bitmap index scan on the idx_person_age_date_active index. It creates the bitmap with all the suitable row locations and passes it to its parent node (that executes after), a Parallel bitmap heap scan on the person table. This second stage goes through the pages individually, executes a Recheck for the filter condition, and returns the result data set.
To compare, consider how the same operation performs using just a sequential scan:
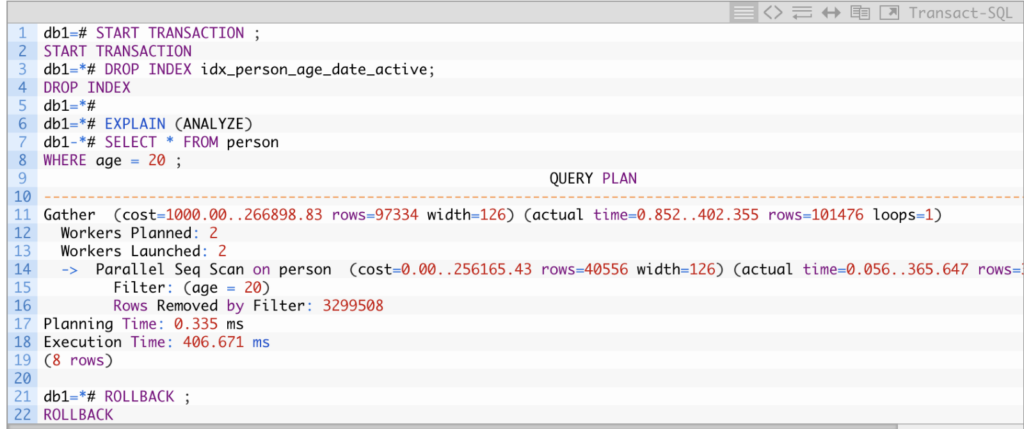
Considering this query went for 101K rows, about 1% of the total rows. The Bitmap index scan took advantage of the “sequential scan” style bulk read over a limited number of pages and produced a better result than a direct Sequential scan, performing 2x faster.
Index scan
It might be the scan method you think about when hearing something like, “Hey, this query is doing good; it uses the index….” This method is the basic definition of accessing the data by an index.
The Index scan consists of two steps, the first is to get the row location from the index, and the second is to gather the actual data from the heap or table pages. Hence, every Index scan access is a two-read operation. But still, this is one of the most efficient ways of retrieving data from a table.
The planner picks this scan method when the number of rows to retrieve is small, so executing the two-step Index Scan operations is “cheaper” and faster than gathering the data by processing the table pages individually.
Using our test table, the following is an example of an Index scan:
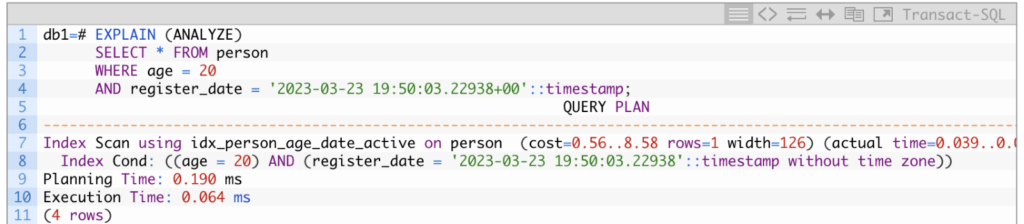
See that in the query we used before, we have added a new filter expression: AND register_date = ‘2023-03-23 19:50:03.22938+00’::timestamp. The register_date column is part of the multicolumn index idx_person_age_date_active. Since we are filtering by a singular value for it, there is one index entry for the same, so PostgreSQL gets the specific row location from the index in one read and then all the row data from the table page within that location. The whole query took 0.064ms; that was fast!
In the above example, the query filters by a specific timestamp value for the register_date column, but PostgreSQL will still choose the Index Scan for multiple rows if the number of rows is small, for example, in the following:
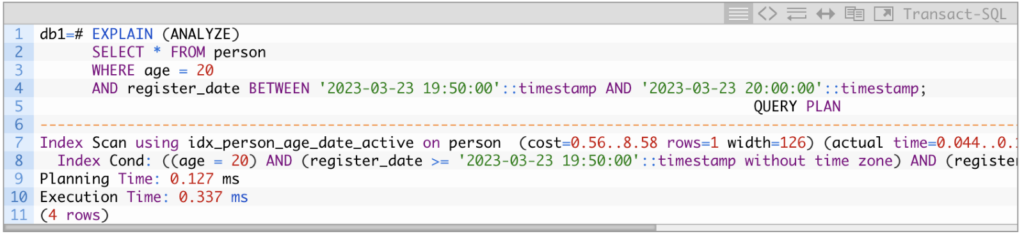
The query filtered the register_date column by a range using the BETWEEN operator. Based on the statistics, the planner thought the result would be one row and chose the Index scan. In the end, the result set was eight rows, so eight pairs of read operations existed. Still, the query was resolved very quickly, with 0.337ms.
Index only scan
Finally, we will review the Index only scan method. This is a really good approach that PostgreSQL uses to improve the standard Index scan method. PostgreSQL uses this method when all the data the query asks for already exists in the index; in other words, the columns/expressions in the SELECT and WHERE clauses should be part of the index so that it is possible to avoid the second read operation to get the data from the table pages and return the result data only from the index read operation.
In the following, we are using almost the same query we used for the Index scan example, but instead of asking for ALL the row columns (*), we are just retrieving the three columns we used to build the multicolumn index:
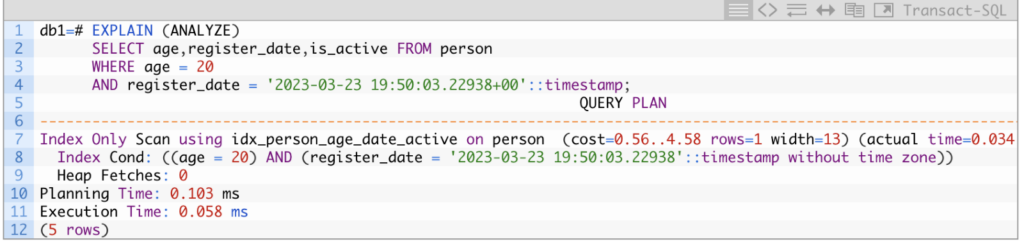
See the EXPLAIN output now says Index Only Scan, and also, it confirms there was no access to the heap (table pages) with the line Heap Fetches: 0. The time was even better than the Index scan from before, only 0.058ms. This scan method can help get the best possible performance for the queries that fit its conditions.
Remember, indexing ALL the columns so the index contains ALL the same data as the table is “not a good idea.” If that is the case, PostgreSQL will not see any advantage of using the index and will pick the sequential scan approach, for example:
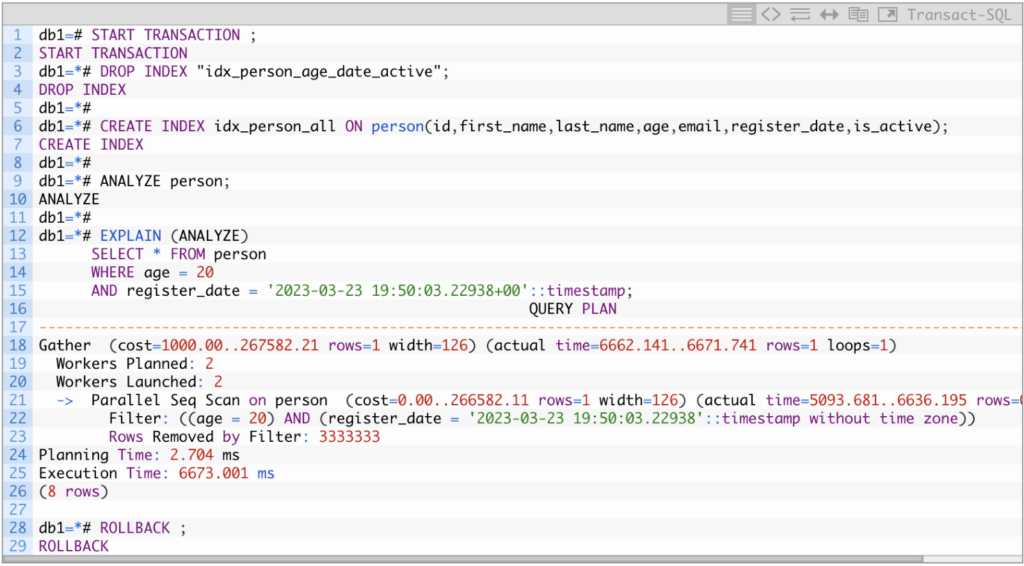
In the above, in a single transaction, we dropped the multicolumn index we used in the previous examples, and created a new one considering ALL the table columns, then refreshed the statistics and tried one query asking for all the columns (*) on a specific filter, as a result, the planner chosen the Sequential scan, it wanted to boost it by executing the operation with parallelism. Still, the final execution time was far from our good results.
Final pieces of advice
Now we have reviewed the different scan options that PostgreSQL can use on a single index depending on the stored data and the query filter conditions. I would like to share some final thoughts that are helpful when planning your query’s filters and table indexes.
- Index the columns with the most cardinality: Following this, your queries can perform best when filtering by the same column. Having indexes on columns with low cardinality will have the opposite effect since it will add extra maintenance, and with high certainty, the planner will not use them.
- Plan your queries for small (specific) data sets rather than larger ones: If your workload and service design afford it, consider filtering your data thinking in retrieving just a few rows. As we saw, the Index Scan is an effective and optimized technique to retrieve data faster, and PostgreSQL will use it if the result data is small enough.
- Retrieve the columns you need only: By doing this, PostgreSQL can leverage Index Only Scan and avoid the “extra” read from the heap (table pages). These saves will produce a notorious good effect in a high query volume environment. Remember that the multicolumn indexes are not the only way to lead the planner to choose the Index Only Scan; you can also consider the covering indexes (matter for another blog, perhaps).
- Tune the random_page_cost parameter: Lowering this will lead the planner to prefer index scans rather than sequential scans. Modern SSD can deliver a better throughput for random read access, so you might analyze adjusting this parameter accordingly.
- Tune the effective_cache_size parameter: Setting this parameter to a higher value (nearly 75% of total RAM if your machine is dedicated to the PostgreSQL service) will help the planner choose index scans over sequential scans.
Remember that every implementation is different, and the details matter, so before adjusting anything in production, it is advisable to analyze and test the effects in a lower environment. If you want to reading more about testing, check out zen8labs blog!
Huy Trinh, Software Engineer