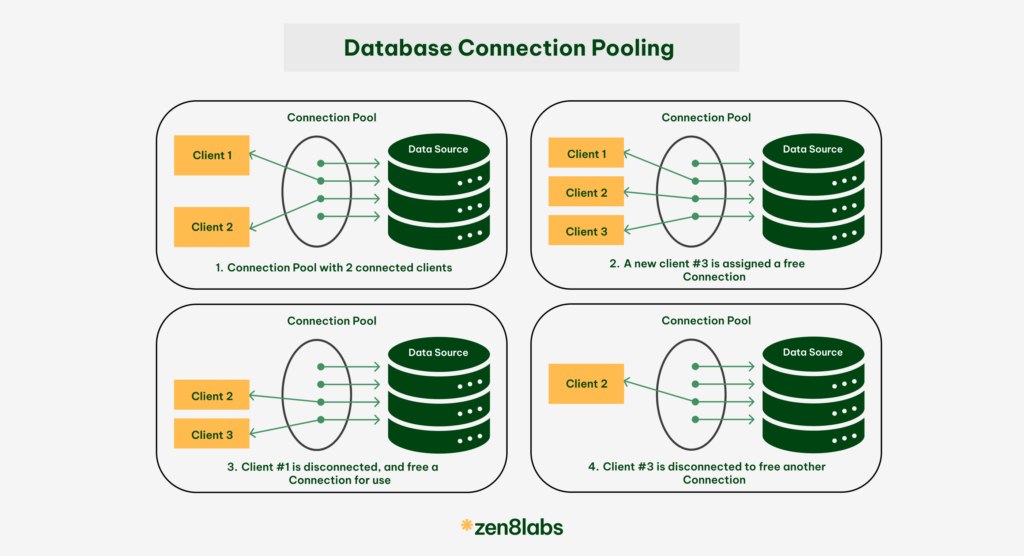
Have you ever considered the importance of database connection pooling? If you have not, then this is the blog for you. Here I will show you some of the quick insights into what is a database connection pool and why it is necessary for using a database connection pooling. I will finally show some simple steps that can help set up your database pool for your success.
1. What is database connection pooling?
Database connection pooling is a technique used to manage and reuse a set of database connections for multiple requests. Instead of opening a new connection for every database query (which is resource-intensive and time-consuming), the application can reuse an existing connection from a pool of pre-established connections. Once a query is executed, the connection is returned to the pool for future use. This greatly reduces the overhead associated with establishing and closing connections, improving the performance of database-driven applications. In short, a connection pool is like a stash of connections that are always available when needed, making the app’s communication with the database quicker and more efficient.
2. Why do we need database connection pooling?
Without connection pooling, every time a user request requires database access, a new connection must be established. Establishing a connection involves network latency, authentication, and resource allocation, all of which can slow down performance, especially when dealing with high concurrency and traffic.
Here’s why connection pooling is essential:
- Reduced latency: Reusing existing connections significantly reduces the time needed to serve user requests since the overhead of creating new connections is avoided.
- Efficient resource utilization: With a fixed number of open connections, the database can handle more queries without exhausting its resources, such as CPU and memory, required to manage multiple concurrent connections.
- Improved scalability: Connection pooling allows applications to scale better by maintaining a stable number of connections, preventing the database from becoming overwhelmed with connection requests.
- Handling high traffic: In environments with high traffic or many concurrent users, connection pooling helps avoid the problem of running out of available connections, which can lead to application downtime.
3. How do we set up database connection pooling?
3.1 Common setups
There are various ways to implement connection pooling depending on your application architecture and database type. Let’s explore some common setups:
- Client-side connection pooling: Client-side libraries and frameworks often provide built-in pooling mechanisms. Here are a few examples:
- Django (Python): Uses connection pooling to manage its database connections through libraries like django-db-geventpool or django-connection-pool.
- HikariCP (Java): A popular high-performance JDBC connection pool used in Java applications. It manages the creation, maintenance, and reuse of database connections.
- Middleware-based connection pooling: Middleware tools like PgBouncer for PostgreSQL act as external connection poolers, providing a layer between the application and the database. These tools manage the actual database connections and handle the pooling logic separately. PgBouncer can run as a lightweight process and handle thousands of connections efficiently by recycling them among clients.
3.2 How to choose Connection Pool Size
- Choosing the right connection pool size is critical for achieving optimal performance. The pool size determines how many connections can be opened simultaneously, and if set too high or too low, it can degrade performance.
- Factors to Consider:
- Number of CPU cores: The number of active threads (and therefore connections) that can be executed concurrently is typically limited by the number of available CPU cores.
- Workload type: High I/O or CPU-intensive queries will benefit from fewer connections, as adding more could overwhelm the system.
- Traffic volume: Applications handling high traffic may need larger pools to prevent connection shortages.
- Latency: In high-latency environments, larger pools may be necessary to ensure there’s always a ready connection.
- Formula to Estimate pool Size:
Optimal Pool Size = Number of CPU Cores × 2 + Number of Disks
This formula ensures that there are enough connections to keep the CPUs busy, while also considering I/O operations.
Conclusion
Database connection pooling has become an essential technique for optimizing the performance of applications that interact with databases. By reusing connections, we can reduce latency, improve resource utilization, and ensure scalability, especially in high-traffic environments. Whether implemented at the client-side, through middleware, or using database features, the key is to configure the pool size based on system resources such as CPU cores and workload demands. If it is done correctly, connection pooling can significantly enhance both the responsiveness and reliability of your database-driven applications. However, I do know that not every database pool can be easy to manage, and that is where zen8labs can step in.
Tung Vu, Software Engineer